21 Mar 2021
Getting into a flow state where your tools get out of the way and you are able to express your thoughts quickly is a great feeling.
This flow can be easily interrupted when things like code completion, syntax highlighting or other IDE support features start to fail.
A function that I find really helps me when I am wanting to get into a good flow and stay there is unimplemented().
The aim is to keep the compiler happy whilst I cut corners and avoid getting bogged down in unimportant details.
TLDR
func unimplemented<T>(message: String = "", file: StaticString = #file, line: UInt = #line) -> T {
fatalError("unimplemented: \(message)", file: file, line: line)
}
Problem
Let’s rewind and go through building the above function step by step as there is a lot in those 3 lines of code that can be applied to other APIs we build.
As an example let’s pretend we have a World structure that contains some globally configured services
struct World {
var analytics: Analytics
var authentication: Authentication
var networkClient: NetworkClient
}
Each one of the services could be quite complicated to construct but for our unit tests we only need to construct the parts under test.
We could create all the instances but this might be awkward/time consuming and also makes the tests less documenting as we are building more than required.
If we had a networkClient that we were testing then the simplest way to get this to compile without providing an Analytics instance and an Authentication instance would be like this:
var Current = World(
analytics: fatalError() as! Analytics,
authentication: fatalError() as! Authentication,
networkClient: networkClient
)
The above isn’t great as the compiler will raise a great big yellow warning on each of the lines containing fatalError as! because the cast will always fail.
Attempt 2
Having big compiler warnings breaks my flow and forces me to go and concentrate on details that are unimportant (this is a complete blocker if you treat warnings as errors).
The next attempt would be to drop the cast so that the compiler doesn’t complain.
To achieve this we need to wrap the call to fatalError in an immediately evaluated closure:
var Current = World(
analytics: { fatalError() }(),
authentication: { fatalError() }(),
networkClient: networkClient
)
The compiler warning is gone but there are a few issues:
- Immediately evaluated closures aren’t the most common thing so people might not remember this trick off the top of their head
- There’s a lot of line noise to type with curly braces and parens
- The error you get from a
fatalError won’t be very descriptive, which makes this technique awkward to use as a TODO list
Attempt 3
Functions are familiar and allow us to give this concept a name. I think a well named function should solve all 3 of the above complaints:
func unimplemented<T>(message: String = "") -> T {
fatalError("unimplemented: \(message)")
}
With the above our call site now looks like this:
var Current = World(
analytics: unimplemented(),
authentication: unimplemented(),
networkClient: networkClient
)
We’ve now got a descriptive function that acts as good documentation that we don’t need two of these arguments for our work.
Having a default message of unimplemented: might not seem very useful but it gives us more indication that this was something we need to implement and not a condition that we never expected to happen (another common use case for fatalError).
Giving this concept a name also means that we have a term we can search for throughout the codebase or logs.
In order for this version to work we’ve had to use a generic placeholder for the return type.
This allows us to leverage type inference to just throw a call to our function in to plug a hole and keep the compiler happy.
Attempt 4
This last version is much nicer than where we started but it actually drops some usability that we got for free in Attempt 2.
With the last version of the code if we actually invoke this function at runtime Xcode will indicate that the unimplemented function is to blame.
It might not be too hard to track back if you have the debugger attached but if not this doesn’t give you much to work with.
When we have the immediately evaluated closures Xcode would highlight the actual line where the fatalError was.
Not to worry as fatalError also accepts file and line arguments.
We simply collect these values and pass them along.
To achieve this we use the literal expression values provided by #file and #line and add them as default arguments:
func unimplemented<T>(message: String = "", file: StaticString = #file, line: UInt = #line) -> T {
fatalError("unimplemented: \(message)", file: file, line: line)
}
Conclusion
I find it really important to take a step back and examine what helps me improve my workflow.
Often taking the time to work through problems helps to stimulate new ideas, find new tools or just highlight bad practices that are slowing me down.
20 Feb 2021
I’ve noticed that a fairly common thing to do in unit tests, especially when isolation isn’t perfect, is to update a value during a test and restore it to its original value after.
This is to avoid leaking state between tests.
Given some poorly isolated code a test case might look something like this:
final class AccountViewControllerTests: XCTestCase {
var initialUser: User?
override func setUp() {
super.setUp()
initialUser = Current.user // Capture the current state
Current.user = .authenticatedUser // Set new state for the test
}
override func tearDown() {
Current.user = initialUser // Restore the original state after the test
super.tearDown()
}
func testLogoutButtonIsVisible() {
let accountViewController = AccountViewController()
accountViewController.loadViewIfNeeded()
accountViewController.viewWillAppear(true)
XCTAssertFalse(accountViewController.logoutButton.isHidden)
}
// More tests
}
This is a lot of busy work and it’s easy to mess up.
Thankfully we can add a small extension to handle the caching dance for us:
extension XCTestCase {
func testCaseSet<T: AnyObject, U>(_ newValue: U, for keyPath: ReferenceWritableKeyPath<T, U>, on subject: T) {
let intitial = subject[keyPath: keyPath]
subject[keyPath: keyPath] = newValue
addTeardownBlock {
subject[keyPath: keyPath] = intitial
}
}
}
Using the above snippet we can more succinctly state that we want to upate a value for the duration of the test and don’t need to worry about how to actually do it.
final class AccountViewControllerWithExtensionTests: XCTestCase {
override func setUp() {
super.setUp()
testCaseSet(.authenticatedUser, for: \.user, on: Current)
}
func testLogoutButtonIsVisible() {
let accountViewController = AccountViewController()
accountViewController.loadViewIfNeeded()
accountViewController.viewWillAppear(true)
XCTAssertFalse(accountViewController.logoutButton.isHidden)
}
// More tests
}
Side note
The original example is long winded and could be made more concise by using addTeardownBlock, which would look like this
final class AccountViewControllerTests: XCTestCase {
override func setUp() {
super.setUp()
let initialUser = Current.user // Capture the current state
Current.user = .authenticatedUser // Set new state for the test
addTeardownBlock {
Current.user = initialUser // Restore the original state after the test
}
}
func testLogoutButtonIsVisible() {
let accountViewController = AccountViewController()
accountViewController.loadViewIfNeeded()
accountViewController.viewWillAppear(true)
XCTAssertFalse(accountViewController.logoutButton.isHidden)
}
// More tests
}
Although this is definitely an improvement it still means the author has to know the pattern and not make a mistake.
Having a higher level abstraction removes the chances of messing things up and hopefully reduces the burden on future readers of the code.
11 Feb 2021
Asynchronous tests are hard and recently I found a new rough edge when using XCTestExpectation.
Take a look at these examples and try to guess the outcome from the following options:
- No tests fail
testA failstestB fails- Both
testA and testB fail
class AsyncTestsTests: XCTestCase {
func testA() throws {
let expectation = self.expectation(description: "async work completed")
asyncFunction { result in
XCTAssertEqual(0, result)
expectation.fulfill()
}
waitForExpectations(timeout: 1)
}
func testB() throws {
let expectation = self.expectation(description: "async work completed")
asyncFunction { _ in
expectation.fulfill()
}
waitForExpectations(timeout: 3)
}
}
func asyncFunction(completion: @escaping (Int) -> Void) {
DispatchQueue.main.asyncAfter(deadline: .now() + 2, execute: { completion(42) })
}
On Xcode 12 both of these tests are flagged as failing, which was very suprising at first.
The code above follows the same flow that the Apple example code demonstrates here, where there are assertions performed within the async callback.
Anecdotally when checking for blog posts on how to use XCTestExpectation they seemed to mostly follow the pattern in the Apple docs with a few exceptions that used the proposed solution below.
What’s happening?
If the tests are run without the random order/concurrent options then testA will be executed before testB.
testA fails because the expectation times out so you get a failure with Asynchronous wait failed: Exceeded timeout of 1 seconds, with unfulfilled expectations: "async work completed"..
The code in testB shouldn’t actually fail but because of the way the assertion in testA is performed in the async callback the timing means that the assertion fails whilst testB is in progress.
This results in Xcode associating the failed assertion with testB.
The following diagram shows a timeline of the above tests and how the assertion from testA bleeds into the execution of testB.
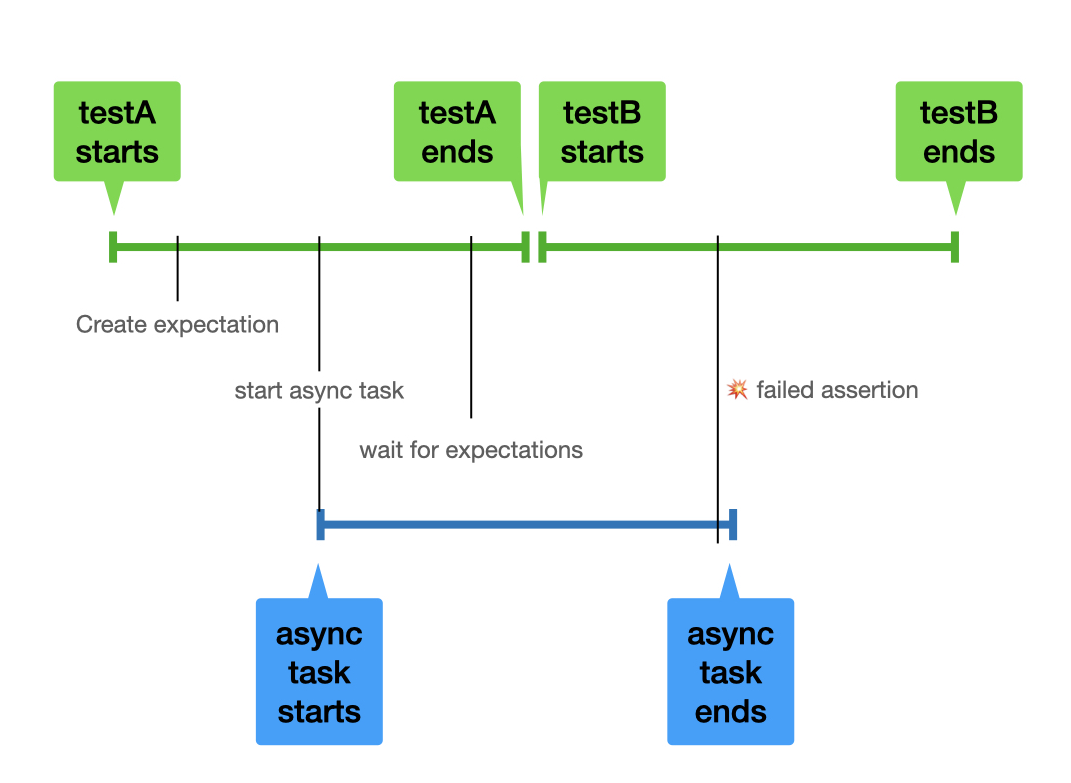
How do I avoid this?
You can avoid this by not performing assertions in the async callback but instead capturing any results and performing the assertions after the wait.
func testA() throws {
let expectation = self.expectation(description: "async work completed")
var capturedResult: Int? = nil
asyncFunction { result in
capturedResult = result
expectation.fulfill()
}
waitForExpectations(timeout: 1)
XCTAssertEqual(0, capturedResult)
}
After making this change the tests now behave as I would expect with testA failing and testB passing.