30 May 2022
Navigating code is one of those things where you accept that it is sometimes painful and slow but just get on it with it without a second thought on how to improve the experience.
I’ve been using Xcode for a long time and I’ve got many different strategies/techniques that help me navigate a project effectively.
Here’s the ones I use most often.
Project navigation
Getting roughly to the right place in a project can be really challenging in a large code base where the project navigator doesn’t fit on one screen.
Here’s the techniques I use for broad brush navigation.
Open quickly
Hitting the combination ⌘+⬆+O will launch the Open quickly dialog box.
This is a good first port of call when you can roughly guess the name of something - start typing and hopefully the list will filter down to what you are looking for or trigger other ideas on what to search.
To make this more powerful I utilise the fact that the search term doesn’t need to be 100% precise for example if I’m looking for a view and have a suspicion it might be named something like HomeView I can straight away include view in my term and just prepend h and I might already get a pretty short candidate list like below:
HeaderView.swift
HomescreenViewController.swift
HelpViewController.swift
HiddenSettingsView.swift
This is often close enough to help me narrow in on what I want.
View debugging
Sometimes I really just can’t figure out what something will be named and that’s where I reach for view debugging.
I can navigate to the screen I want to locate the source for on a device/simulator and then hit the Capture View Hierarchy button in the Xcode debugging toolbar.
Now I can navigate around the view hierarchy and see the names of views and view controllers.
Once I have the name I go back to the trusty Open quickly dialog and I’m there.
This is such a simple technique but really powerful - I’ve recently been retrospectively adding accessibility ids to a large old codebase and this has really allowed me to drill in quickly make changes and move on.
Project find
Hitting ⌘+⬆+F lands you on the Project find pane where you can execute various searches of your project.
There’s loads of options you can play with that I won’t cover here but it’s worth familiarising yourself with all the capabilities.
The settings I play with most often are scopes to only search in certain projects/folders or changing to regex for when plain text search isn’t flexible enough.
Bonus tip: You can delete the items in the search results by selecting it and hitting back space.
This allows me to treat a search like a todo list I can filter down as I do work.
Filter bar
At the bottom of the Project navigation pane there is a filter bar which I don’t use often but when I do it’s very handy.
Being able to hit the +- button and filter by only files that have source control changes is great when you want to focus on tidying up work before committing.
Reveal in project
Once I’ve found a helpful class I instinctively hit ⌘+⬆+J to reveal in project.
This expands the Project Navigator to show where the file is located, this is often helpful as related code tends to be grouped together.
Seeing the file you are looking at in the context of similar classes can often help ground you and give you an idea of other things you might need to explore.
In file navigation
The challenges with navigation don’t necessarily stop once you’ve found a source file.
Here’s the tricks I use when navigating in a single file.
Jump bar
If I’m new to a class and I want to see what methods it has available my go to technique is to use the jump bar with ctrl+6.
This jump bar lists all the methods available and just like Open quickly I can start to filter the methods without needing to be too precise with my guess.
This is a great way to get a sense of how a class is structured and filter to methods of relevance quickly.
Search
We can hit ⌘+F (without the ⬆) to search within a file.
This is great but often I am searching for a word I have highlighted so if I use this technique I actually need to do ⌘+C, ⌘+F, ⌘+V and then hit enter.
That’s far too much effort luckily if you have a word selected you can hit ⌘+E to add the word to the global search and then hit ⌘+G to cycle through the matches.
If you go too far or have a feeling that navigating bottom to top would be faster then add a shift into the mix to change direction ⌘+⬆+G.
Bonus tip: ⌘+E is the global search so most well behaved text fields on a mac will work with this e.g. I can select a word in Safari hit ⌘+E then go to Xcode and cycle through matches with ⌘+G.
Jump to definition
A large percentage of our time is spent reading and understanding code.
The ultimate short cut for this is ⌘+^+j to navigate to the code that defined a symbol or a method.
Bonus tip: jumping around is great if you can find your way back so remember ⌘+^+← to jump back in your navigation stack and ⌘+^+→ to navigate forwards.
Undo/Redo
In large files it’s often the case that you can be writing code in one place and then need to reference another part of the same file - probably using a combination of these techniques.
Instead of trying to find my way back to the code I was working on by manually scrolling I instead hit ⌘+Z to undo my last change and then immediately hit ⌘+⬆+Z to redo the change.
This combination might seem pointless but the side effect is that the editor will jump the caret back to the place being edited.
Conclusion
There’s loads of ways to navigate - the above list isn’t exhaustive it’s just the things I use most often.
I love watching other people develop and I’m often the annoying person stopping things to say “what was the keyboard shortcut” or “how did you do that”.
The above is my attempt to share some things that I would find interesting if someone else did it in front of me.
27 Apr 2022
Like all programming there are many ways to solve any problem and I saw a comment that had a pretty neat, more Excelesque way (I think - I’m not an Excel user) of solving the problem.
To drive home the benefit of testing this post adds a couple of tests to the current approach, then I’ll rewrite the solution entirely but keep the tests the same.
If all goes well the formula will be completely different but my level of confidence in the calculation will still be high as it satisfies my assumptions that I encoded in some tests.
Let’s add some tests
For a post that was about testing I shockingly didn’t test the final formula 🤦🏼♂️, which currently looks like this
=Pair.First(REDUCE(PairMake(0,Data!A1),Data!A1:Data!A2000,NextPartialResult))
The PairMake function and NextPartialResult function had tests written but the whole thing did not.
Therefore it’s not safe for me to just change the above formula until I get it behind some tests.
For testing this I’m going to use my current data set and pick different slices of it to produce different results from the formula:
| |
A (Formula) |
A (Result) |
B |
C (Formula) |
C (Result) |
D |
E |
F |
| 1 |
Actual |
Actual |
Expected |
Result |
Result |
Result Text |
|
199 |
| 2 |
=SolveTask1(F1:F10) |
7 |
7 |
=Assert.Equals(B2,C2) |
✅ |
|
|
200 |
| 3 |
=SolveTask1(F8:F10) |
1 |
1 |
=Assert.Equals(B3,C3) |
✅ |
|
|
208 |
| 4 |
=SolveTask1(F3:F10) |
5 |
5 |
=Assert.Equals(B4,C4) |
✅ |
|
|
210 |
| 5 |
|
|
|
|
|
|
|
200 |
| 6 |
|
|
|
|
|
|
|
207 |
| 7 |
|
|
|
|
|
|
|
240 |
| 8 |
|
|
|
|
|
|
|
269 |
| 9 |
|
|
|
|
|
|
|
260 |
| 10 |
|
|
|
|
|
|
|
263 |
With the above I can massage my original solution into a named function called SolveTask1 (naming is hard) that will make all the above tests pass.
SolveTask1 = LAMBDA(range,
Pair.First(REDUCE(PairMake(0,OFFSET(range,0,0,1)),range,NextPartialResult))
);
Throw everything away and write again
With these tests in place I have a level of confidence that if I call SolveTask1 then it should behave as long as I keep the same tests.
The solution I’m going to implement (there could be many more) is based on a comment from twobitshifter who suggested ={SUM(—-(A1:A1999<A2:2000)}.
If I rejig the suggested formula to work in a named function I come up with the following that also passes my tests
SolveTask1 = LAMBDA(range,
SUM(--(OFFSET(range,0,0,ROWS(range) - 1)<OFFSET(range,1,0,ROWS(range) - 1)))
);
This is a real improvement as I’ve got my final calculation behind some tests that gives me confidence.
It also means I can delete all the old tests from my previous post and remove the NextPartialResult helper function entirely - throwing code away is a good thing as less code = less bugs.
Of course we don’t have to stop right there, I might look at the solution above and not be happy about the duplication of ROWS(range) - 1.
Because this is all tested I can very quickly introduce a LET and as all of my tests still pass I know I didn’t fudge something up whilst making the change.
SolveTask1 = LAMBDA(range,
LET(
sliceSize, ROWS(range) - 1,
SUM(--(OFFSET(range,0,0,sliceSize)<OFFSET(range,1,0,sliceSize)))
)
);
Conclusion
I was able to take a working formula and change it a few times without worrying if I was going to break anything.
The first change was a complete rewrite and change of approach and the second change was more of an iterative improvement.
Having the tests present gave me the confidence to make broad changes without needing to go and do a load of manual verification or to spend forever statically analysing the code to guess that it still works.
25 Apr 2022
For some reason I decided it would be fun to attempt Day 1 of the Advent of Code 2021 using Excel’s Lambdas, whilst unit testing as I go - here’s how that went.
The challenge can be summarised as - go through a list of values and keep track how many times the latest value is larger than the value before it.
For example given this list:
199
200
208
210
200
207
240
269
260
263
We can step through the values observing whether the value increased or decreased
199 (N/A - no previous measurement)
200 (increased)
208 (increased)
210 (increased)
200 (decreased)
207 (increased)
240 (increased)
269 (increased)
260 (decreased)
263 (increased)
Our task is to tally how many times the value increased - in the above that would be 7.
Reduce a list to a single value
In order to perform the calculation I’m going to need to use Excel’s REDUCE function.
REDUCE takes an initial value, the range we want to enumerate and a LAMBDA that is used to combine the values together.
A small worked example might help
=REDUCE(0, {1,2,3}, LAMBDA(acc, value, acc + value))
The expression above will evaluate to 6 but let’s try and visualise what is happening.
We have 3 items in our array which means that the combining function is going to be called 3 times - I can show this with some boxes representing each step:
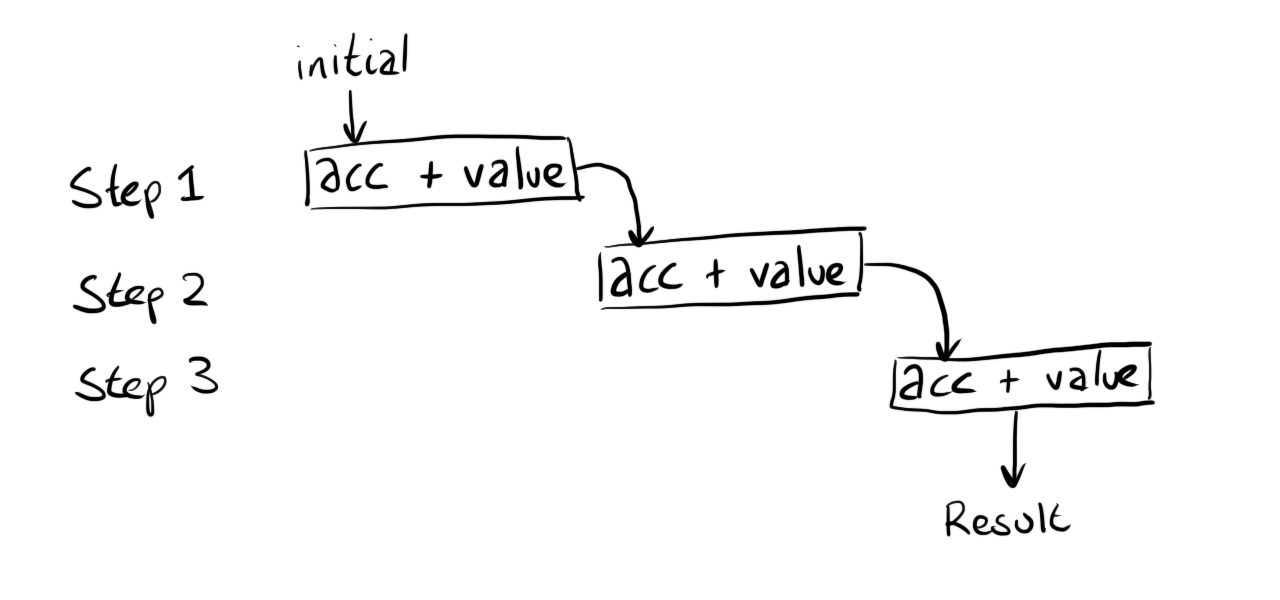
If we substitute the values that were passed to the function ({1,2,3}) the diagram looks like this:
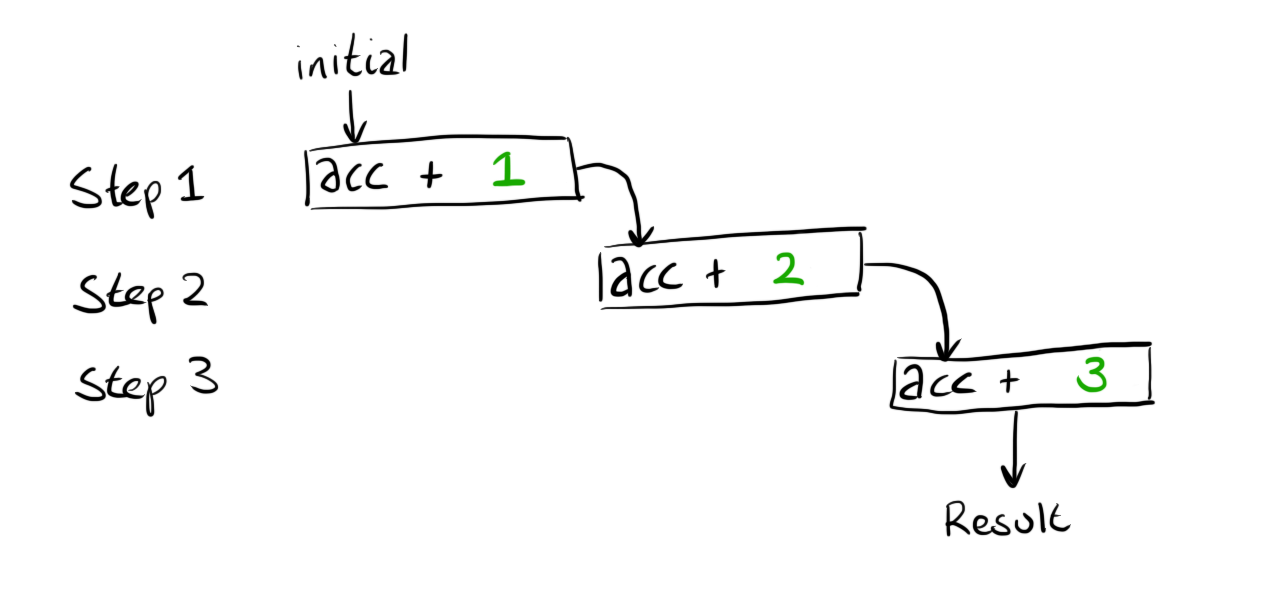
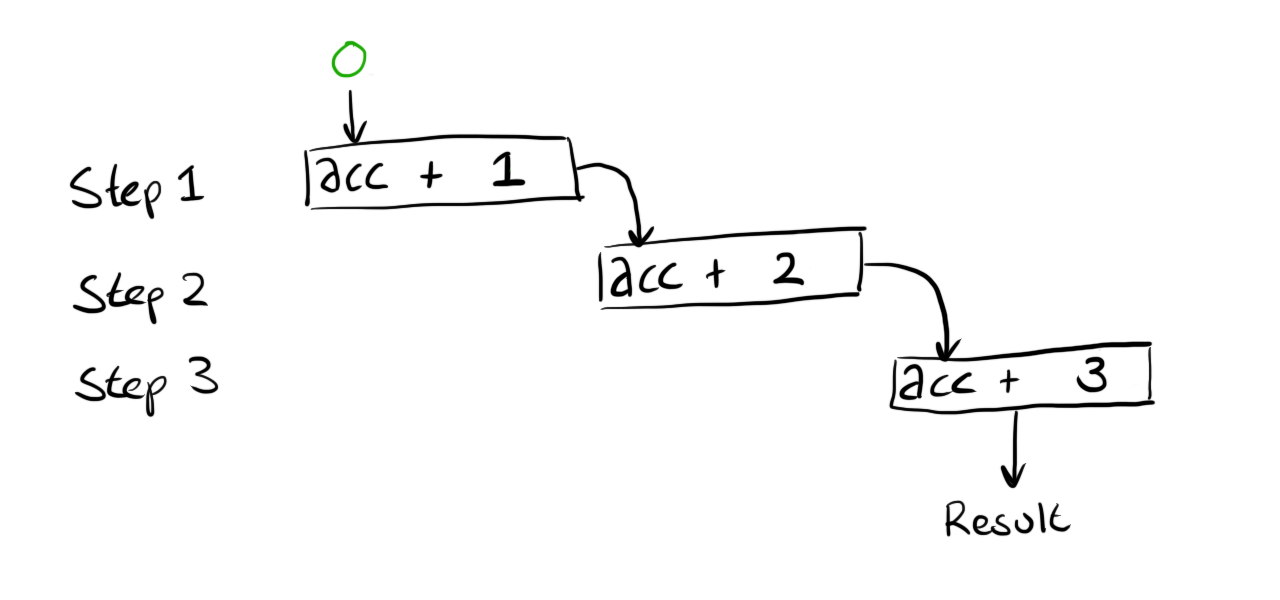
We can’t compute the result because the first calculation still needs a value for acc.
This value is provided as the first argument to our call to REDUCE which gives this:
Finally we can perform all the calculations and get the final result of 6.
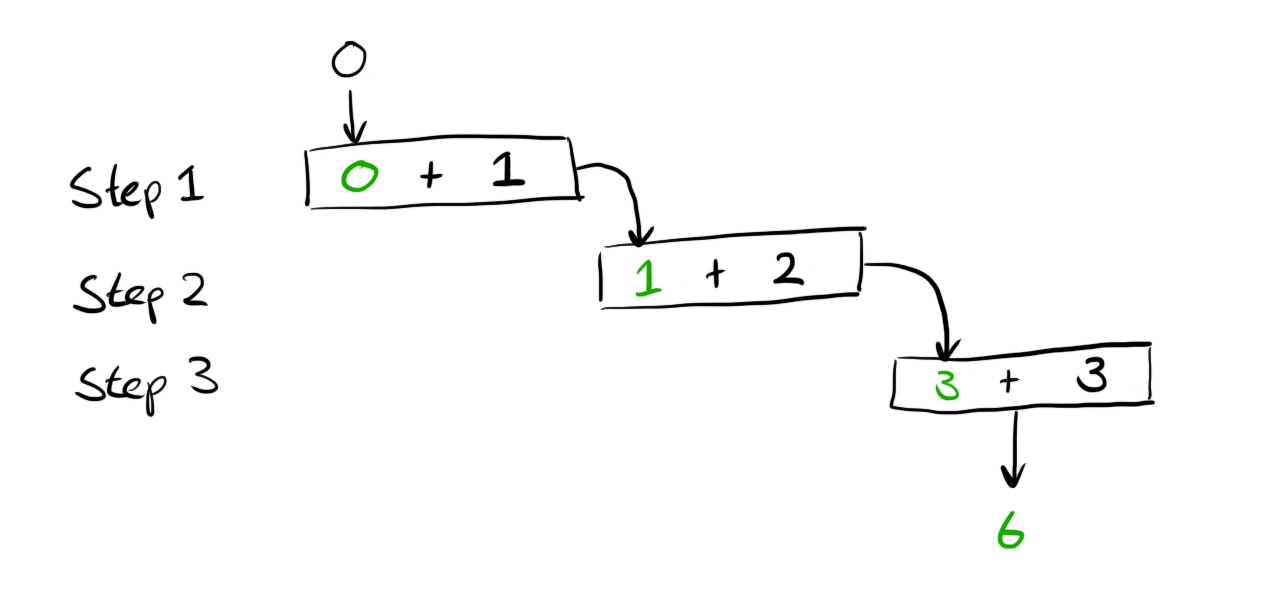
The above example is obviously not something we’d want to ever use, especially as it’s a long winded way of writing =SUM(1,2,3) but it shows how REDUCE is performing all the iteration for us and we just have to provide a combining function to tailor the behaviour.
Working around single value returns
Unfortunately REDUCE alone won’t quite get us what we need.
When we iterate over the list we actually need to keep track of two pieces of data, the current count of increments and the previous value we’ve seen.
As seen above REDUCE only keeps track of a single value in the variable we called acc.
The way I’m going to work around this restriction is to create a Pair abstraction.
I’m going to create a few helper functions that work on arrays with the expectation that the array only ever has 2 elements.
I’ll start by writing some tests for these functions in a new sheet called PairTests.
| |
A (Formula) |
A (Result) |
B |
C (Formula) |
C (Result) |
| 1 |
Actual |
Actual |
Expected |
Result |
Result |
| 2 |
=ARRAYTOTEXT(PairMake(0,0)) |
0, 0 |
0, 0 |
=Assert.Equals(B2,C2) |
|
| 3 |
=ARRAYTOTEXT(PairMake(0,1)) |
0, 1 |
0, 1 |
=Assert.Equals(B3,C3) |
|
| 4 |
=ARRAYTOTEXT(PairMake(1,1)) |
1, 1 |
1, 1 |
=Assert.Equals(B4,C4) |
|
The above tests are verifying that a function called PairMake can create arrays correctly.
*I’m using ARRAYTOTEXT to make the assertion a little easier to write
**Naming is hard and PairMake is the best I could come up ¯\_(ツ)_/¯
To make this test pass I can write the formula as
PairMake = lambda(x,y,MAKEARRAY(1,2,lambda(_, col,IF(col=1,x,y))));
This function mainly exists to hide all the ugly MAKEARRAY stuff - there may be much easier ways to create an array with dynamic input but my googlefu was not working and I wanted to move on.
The Assert.Equals function I’m calling is defined like this:
Assert.Equals = LAMBDA(actual, expected, if(actual=expected, "", "Expected '" & expected & "' but got '" & actual & "'"));
This does the job but because there is no output on success it is not obvious if anything is happening.
Luckily I’ve just created a Pair type so I can improve the assert function by returning pairs where the first value is a pretty emoji ✅ or ❌ and the second value is empty in the success case or the helpful error message in the failure case.
Assert.Equals = LAMBDA(actual, expected, if(actual=expected, PairMake("✅",""), PairMake("❌","Expected '" & expected & "' but got '" & actual & "'")));
After refreshing the previous table now looks healthier and shows some calculation is actually being done
| |
A (Formula) |
A (Result) |
B |
C (Formula) |
C (Result) |
| 1 |
Actual |
Actual |
Expected |
Result |
Result |
| 2 |
=ARRAYTOTEXT(PairMake(0,0)) |
0, 0 |
0, 0 |
=Assert.Equals(B2,C2) |
✅ |
| 3 |
=ARRAYTOTEXT(PairMake(0,1)) |
0, 1 |
0, 1 |
=Assert.Equals(B3,C3) |
✅ |
| 4 |
=ARRAYTOTEXT(PairMake(1,1)) |
1, 1 |
1, 1 |
=Assert.Equals(B4,C4) |
✅ |
Next up I want to define two more functions to complete the illusion that I have a Pair and hide the fact that I’m just using an Array.
| |
A (Formula) |
A (Result) |
B |
C (Formula) |
C (Result) |
| 1 |
Actual |
Actual |
Expected |
Result |
Result |
| 2 |
=Pair.First({“first”,”second”}) |
first |
first |
=Assert.Equals(B2,C2) |
✅ |
| 3 |
=Pair.Second({“first”,”second”}) |
second |
second |
=Assert.Equals(B3,C3) |
✅ |
Having functions to grab both the elements from the Pair means I don’t need to mess with INDEX everywhere and ruin the illusion that I have an honest Pair type.
Under the hood these functions do in fact just use INDEX
Pair.First = lambda(pair,INDEX(pair,1));
Pair.Second = lambda(pair,INDEX(pair,2));
Actually solving the challenge
The above was a lot of scaffolding/understanding that means we are now able to get to the task at hand.
As a recap we are going to use REDUCE to iterate over some data, whilst iterating we are going to keep track of the current count of increases and the previous value we are working with.
Once the iteration is done we can discard the previous value and just pluck out the count we have been accumulating.
Assuming the data is contained in a sheet named Data let’s see how this all looks plumbed together
=Pair.First(
REDUCE(
PairMake(0,Data!A1),
Data!A1:Data!A10,
??????
)
)
Our reduce is going to produce a Pair where the first element is the count and the second element is the previous value.
We don’t care about the previous element at the end of our calculation so we just pluck out the first value by wrapping the REDUCE in a call to Pair.First.
The first argument to REDUCE is the initial value - above we are creating a Pair where the first element represents the count starting at 0.
The second element represents the previous value, which we are setting to the first value in the list.
This is because if you look at the problem example at the top of this post the first item does not count as an increment as there was no previous value.
The second argument to REDUCE is the data range - nothing to explain here.
The third argument is MIA.
I’ve jumped ahead too much and we probably need to figure out the behaviour of this combining function by writing some tests.
The combining function
The combining function will be called for each element in the array.
Each time we will have available the count of increments + the previous value wrapped in a pair and the current value.
The combining function needs to figure out if the increasing count needs incrementing and then it always needs to return the current value.
These two pieces of information are then fed into the next round of calculation and so on until we reach the end of our collection.
We can express these requirements with 3 tests:
| |
A (Formula) |
A (Result) |
B |
C (Formula) |
C (Result) |
| 1 |
Actual |
Actual |
Expected |
Result |
Result |
| 2 |
=ARRAYTOTEXT(NextPartialResult({0,0},1)) |
1, 1 |
1, 1 |
=Assert.Equals(B2,C2) |
|
| 3 |
=ARRAYTOTEXT(NextPartialResult({0,1},1)) |
0, 1 |
0, 1 |
=Assert.Equals(B3,C3) |
|
| 4 |
=ARRAYTOTEXT(NextPartialResult({1,2},1)) |
1, 1 |
1, 1 |
=Assert.Equals(B4,C4) |
|
The test in Row 2 checks that the count is incremented when the current value is bigger than the previous.
The test in Row 3 checks that the count is not incremented when the current value is equal to the previous.
The test in Row 4 checks that the count is not incremented when the current value is less than the previous.
A function that satisfies these tests could look like this
NextPartialResult = LAMBDA(acc, value,
Let(
count, Pair.First(acc),
previous, Pair.Second(acc),
if(
previous<value,
PairMake(count+1,value),
PairMake(count,value)
)
)
);
Plumbing it all together
With all the above we can now complete the task by filling out the ?????? in our previous attempt
=Pair.First(
REDUCE(
PairMake(0,Data!A1),
Data!A1:Data!A10,
NextPartialResult
)
)
We can now sit back and marvel at the glowing number 7 that we could have calculated by hand on such a small data set with considerably less effort.
Thankfully the actual challenge has a data set with 2000 lines and seeing the work above calculate correctly against the full data set is much more rewarding.
If you got this far and you are thinking that you could solve the problem in a simpler way using a different formula then check out the next post where I do exactly that but in a controlled way using tests to ensure a completely different formula behaves identically.